利用自动化测试工具Selenium爬取IEEE的学者信息
自动化测试——Selenium
What is Selenium?
Selenium automates browsers. That’s it! What you do with that power is entirely up to you. Primarily, it is for automating web applications for testing purposes, but is certainly not limited to just that. Boring web-based administration tasks can (and should!) be automated as well.
Selenium has the support of some of the largest browser vendors who have taken (or are taking) steps to make Selenium a native part of their browser. It is also the core technology in countless other browser automation tools, APIs and frameworks.
应用背景
在许多场景下,测试人员需要自动化测试工具来提高测试效率,Selenium 就是一款专为浏览器自动化测试服务的工具。它可以完全模拟浏览器的各种操作,以此把程序员从繁重的 cookie、 header、 request 等等中解放出来。
为什么我要用到 Selenium ?在小灯神的心愿上接了个活,学妹要求爬取 IEEEXplore 网站上某个学者的所有论文(标题、来源、关键词),而这个网站又是异步加载的,所以普通的爬虫根本爬不到数据,在网上搜索了一下,需要抓去 js 包,然而我几乎没怎么学过 js,放弃这个方法,听说还可以用 Selenium 自动化获取,于是开始学习 Selenium。
环境搭建
在 Selenium 官网上下载对应浏览器的 driver ,比如我用的是 chrome 浏览器,就下载 chromedriver,下载地址:https://sites.google.com/a/chromium.org/chromedriver/downloads。可能需要FQ,自行备梯子,或者去找国内镜像。
把 chromedriver.exe 放在项目根目录下即可,接下来看看要如何操作这个驱动。
官网有 getting start:https://sites.google.com/a/chromium.org/chromedriver/getting-started,放上 Python 版本的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14# Python:
import time
from selenium import webdriver
import selenium.webdriver.chrome.service as service
service = service.Service('/path/to/chromedriver')
service.start()
capabilities = {'chrome.binary': '/path/to/custom/chrome'}
driver = webdriver.Remote(service.service_url, capabilities)
driver.get('http://www.google.com/xhtml');
time.sleep(5) # Let the user actually see something!
driver.quit()实际上不需要官方教程那么复杂,如下代码可以直接打开受自动化工具控制的 chrome:
1
2
3from selenium import webdriver
driver = webdriver.Chrome(executable_path='chromedriver.exe')运行上面两行代码,且 exe 文件位于同一文件夹下,则可以看到 chrome 浏览器 打开了
至此,环境搭建成功。
Selenium 基础操作
有人做了 doc 中文文档,可以参阅一下:http://python-selenium-zh.readthedocs.io/zh_CN/latest/
打开某个网页:
1
driver.get("http://www.baidu.com")
其中 driver.get 方法会打开请求的URL,WebDriver 会等待页面完全加载完成之后才会返回,即程序会等待页面的所有内容加载完成,JS渲染完毕之后才继续往下执行。注意:如果这里用到了特别多的 Ajax 的话,程序可能不知道是否已经完全加载完毕。
寻找某个网页元素:
1
2
3
4
5
6
7
8find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector寻找某组网页元素:
1
2
3
4
5
6
7find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector假设有这样一个输入框:
1
<input type="text" name="passwd" id="passwd-id" />
以下几种方法都可以找到它(但不一定是唯一的):
1
2
3
4element = driver.find_element_by_id("passwd-id")
element = driver.find_element_by_name("passwd")
element = driver.find_elements_by_tag_name("input")
element = driver.find_element_by_xpath("//input[@id='passwd-id']"获取元素后,元素本身并没有价值,它包含的文本或者链接才有价值:
1
2text = element.text
link = element.get_attribute('href')获取了元素之后,下一步当然就是向文本输入内容了,可以利用下面的方法
1
element.send_keys("some text")
同样你还可以利用 Keys 这个类来模拟点击某个按键。
1
element.send_keys("and some", Keys.ARROW_DOWN)
输入的文本都会在原来的基础上继续输入。你可以用下面的方法来清除输入文本的内容。
1
element.clear()
下拉选项框可以利用 Select 方法:
1
2
3
4
5
6
7
8
9
10from selenium.webdriver.support.ui import Select
select = Select(driver.find_element_by_name('name'))
select.select_by_index(index)
select.select_by_visible_text("text")
select.select_by_value(value)
select.deselect_all()
all_selected_options = select.all_selected_options提交表单:
1
driver.find_element_by_id("submit").click()
Cookie 处理:
1
2
3
4cookie = {‘name’ : ‘foo’, ‘value’ : ‘bar’}
driver.add_cookie(cookie)
driver.get_cookies()页面等待:
这是非常重要的一部分,现在的网页越来越多采用了 Ajax 技术,这样程序便不能确定何时某个元素完全加载出来了。这会让元素定位困难而且会提高产生 ElementNotVisibleException 的概率。
所以 Selenium 提供了两种等待方式,一种是隐式等待,一种是显式等待。
隐式等待是等待特定的时间:
1
driver.implicitly_wait(10) # seconds
显式等待是指定某一条件直到这个条件成立时继续执行,常用的判断条件:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17title_is 标题是某内容
title_contains 标题包含某内容
presence_of_element_located 元素加载出,传入定位元组,如(By.ID, 'p')
visibility_of_element_located 元素可见,传入定位元组
visibility_of 可见,传入元素对象
presence_of_all_elements_located 所有元素加载出
text_to_be_present_in_element 某个元素文本包含某文字
text_to_be_present_in_element_value 某个元素值包含某文字
frame_to_be_available_and_switch_to_it frame加载并切换
invisibility_of_element_located 元素不可见
element_to_be_clickable 元素可点击
staleness_of 判断一个元素是否仍在DOM,可判断页面是否已经刷新
element_to_be_selected 元素可选择,传元素对象
element_located_to_be_selected 元素可选择,传入定位元组
element_selection_state_to_be 传入元素对象以及状态,相等返回True,否则返回False
element_located_selection_state_to_be 传入定位元组以及状态,相等返回True,否则返回False
alert_is_present 是否出现Alert官方 API :http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions
浏览器的前进和后退:
1
2driver.back()
driver.forward()
IEEEXplore 实战
-
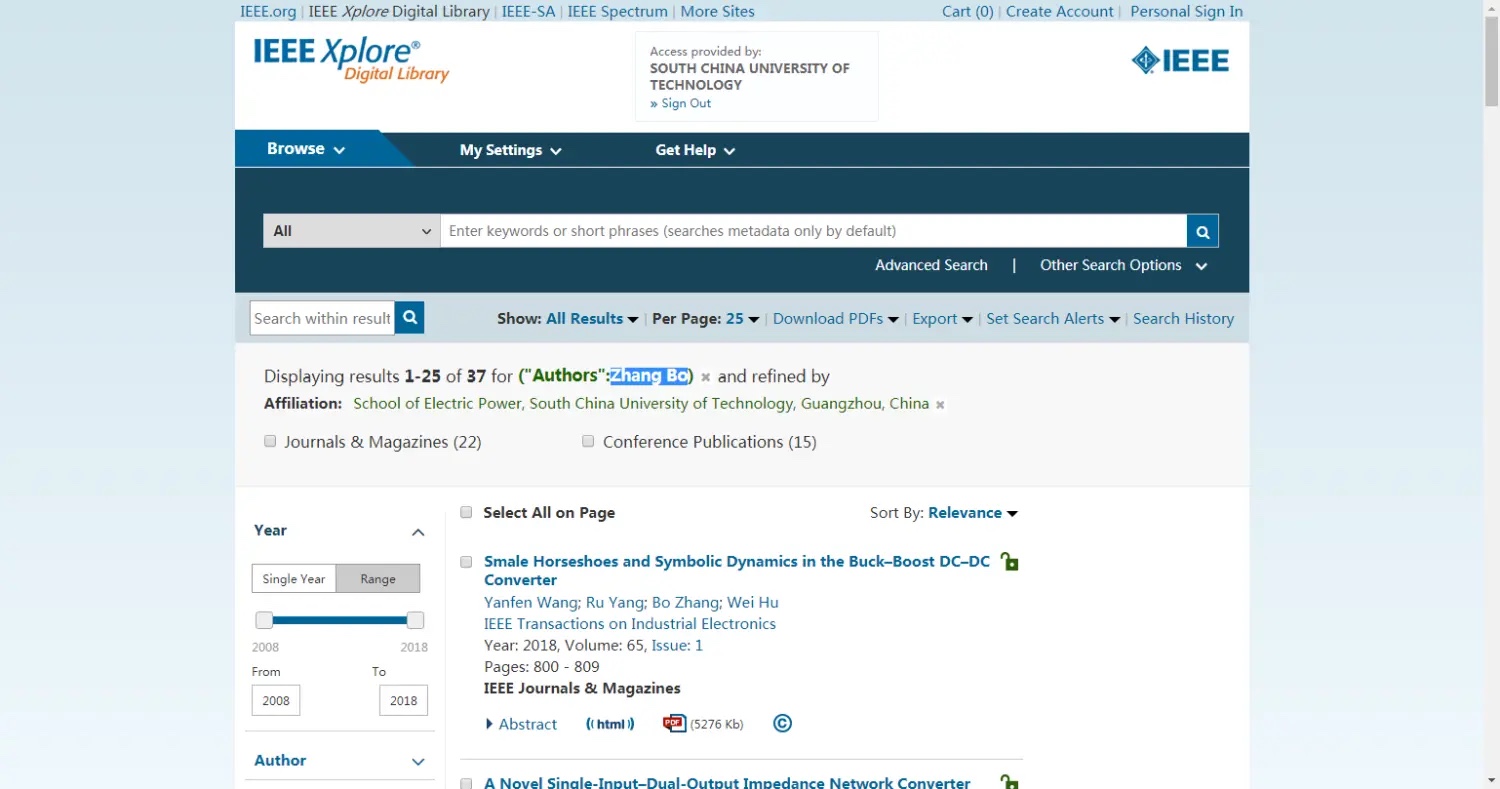
它显示了学者:Zhang Bo 的所有文章列表(分为两页),我们要爬取的首先是论文标题,这个比较简单,来源也比较简单,比如上图的第一篇文章标题为:Smale Horseshoes and Symbolic Dynamics in the Buck–Boost DC–DC Converter,来源为:IEEE Transactions on Industrial Electronics。
可以通过 find_elements_by_css_selector 来找到这样的一组元素:
1
2
3
4
5
6
7
8
9
10
11
12
13
14article_name_ele_list = driver.find_elements_by_css_selector("h2 a.ng-binding.ng-scope") # 获取该页面所有文章标题的元素
for article_name_ele in article_name_ele_list: # 对每个文章标题元素,提取标题文本(字符串),以及文章 url
article_name = article_name_ele.text
article_link = article_name_ele.get_attribute('href')
article_names.append(article_name)
print("article_name = ", article_name)
article_links.append(article_link)
print("article_link = ", article_link)
article_source_ele_list = driver.find_elements_by_css_selector("div.description.u-mb-1 a.ng-binding.ng-scope") # 获取该页面所有文章来源的元素
for article_source_ele in article_source_ele_list: # 对每个文章来源元素,提取来源文本(字符串)
article_source = article_source_ele.text
article_sources.append(article_source)
print("article_source =", article_source)它的翻页操作比较蛋疼,底部虽然有页码工具条,但是都用到了 on-click 方法,然后方法内传入一个自定义的函数,这又是 js 的内容,有点麻烦。后来我注意到 url 地址变化的规律。
入口(也就是第一页)是这样的:
1
http://ieeexplore.ieee.org/search/searchresult.jsp?queryText=(%22Authors%22:Zhang%20Bo)&refinements=4224983357&matchBoolean=true&searchField=Search_All
第二页是这样的:
1
http://ieeexplore.ieee.org/search/searchresult.jsp?queryText=(%22Authors%22:Zhang%20Bo)&refinements=4224983357&matchBoolean=true&pageNumber=2&searchField=Search_All
也就多了一个 pageNumber 的参数,如果手动输入 pageNumber 是3的话,是什么样的呢?
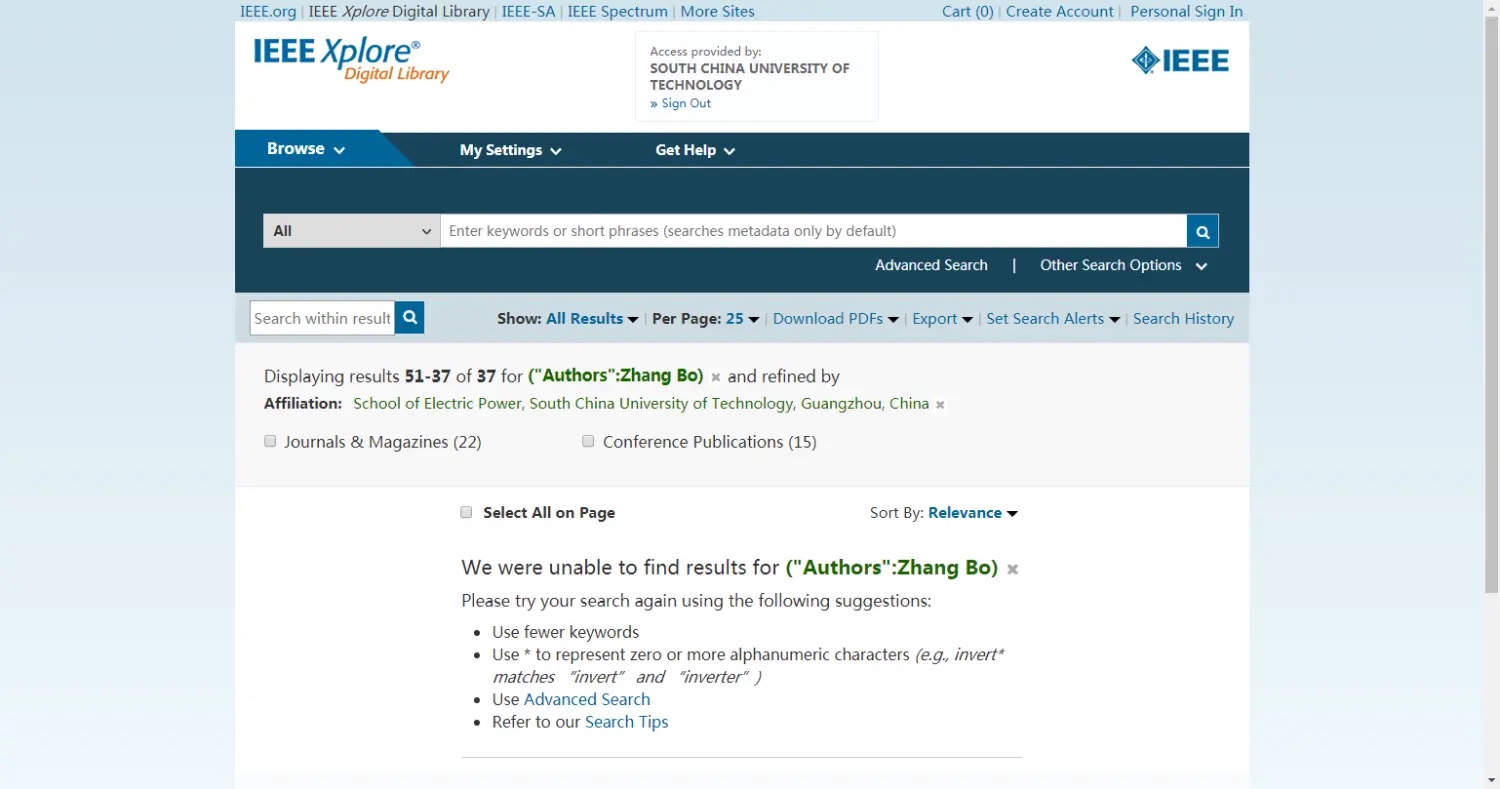
这样我就根本不用管页码工具条,靠 url 跳转就可以实现翻页的效果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30pageNumber = 1
while(True):
driver.get(
'http://ieeexplore.ieee.org/search/searchresult.jsp?queryText=(%22Authors%22:Zhang%20Bo)&refinements=4224983357&matchBoolean=true&pageNumber=' + str(pageNumber) + '&searchField=Search_All')
time.sleep(5)
print("start to check if this is the last page !!!")
try:
driver.find_element_by_css_selector("p.List-results-none--lg.u-mb-0") # if this is NOT the last page, this will raise exception
except Exception as e:
print("This page is good to go !!!")
else:
print("The last page !!!")
break
article_name_ele_list = driver.find_elements_by_css_selector("h2 a.ng-binding.ng-scope")
for article_name_ele in article_name_ele_list:
article_name = article_name_ele.text
article_link = article_name_ele.get_attribute('href')
article_names.append(article_name)
print("article_name = ", article_name)
article_links.append(article_link)
print("article_link = ", article_link)
article_source_ele_list = driver.find_elements_by_css_selector("div.description.u-mb-1 a.ng-binding.ng-scope")
for article_source_ele in article_source_ele_list:
article_source = article_source_ele.text
article_sources.append(article_source)
print("article_source =", article_source)
pageNumber += 1解释:
首先初始化为第一页,然后进入 while 循环,首先会检查当前页面是否是 notfound 页面,如果是,则证明上一页已经是最后一页了,跳出循环。如果不是才获取文章标题、文章链接、文章来源,最后另 pageNumber 加一即可。
获取文章关键词
好的,万事开头难,我们已经有这位学者20篇论文的链接了,我们要一一打开这些链接,获取其中的关键词。但是我们打开第一篇文章的链接,发现默认可以看到“Abstract”,还需要点击“Keywords”才行
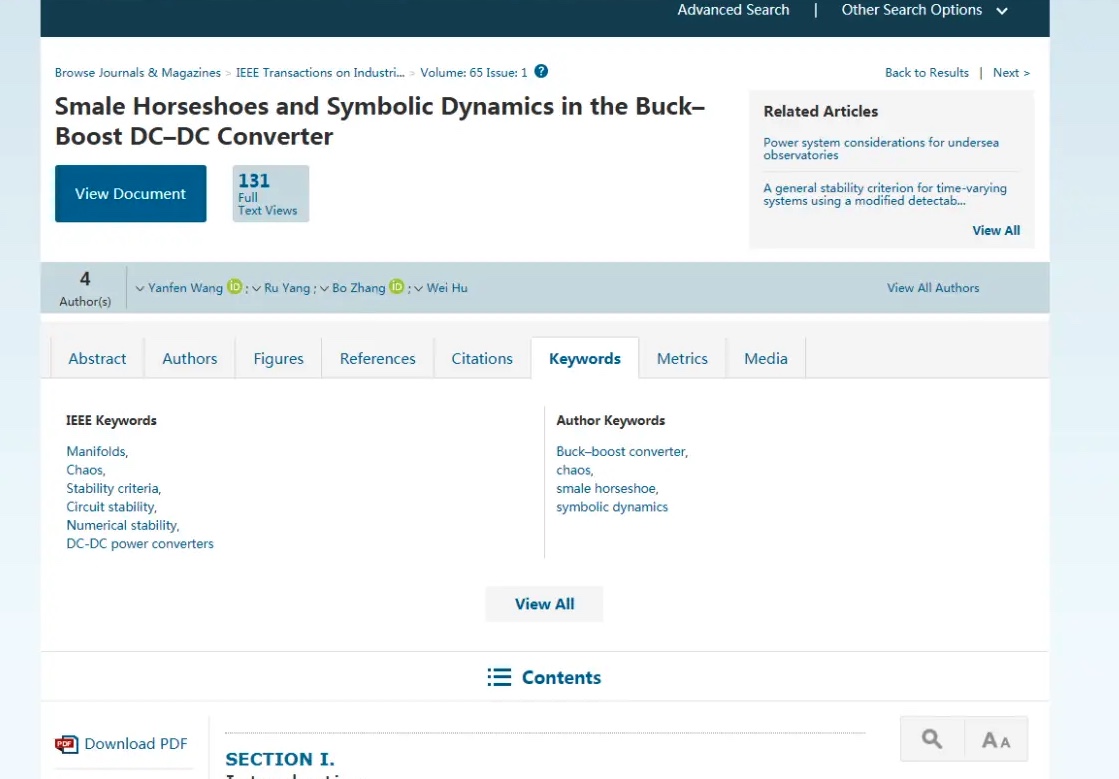
但是观察 url,真是天助我也,只需要加入‘/keywrods’就好了。
但是这些关键词要在怎么获取呢?值得一提的是,这篇文章的关键词有两类:IEEE Keywords, Author Keywords。有的文章不止这两类,还有可能有:INSPEC: Controlled Indexing, INSPEC: Non-Controlled Indexing。
就算获取到了这四个,但是关键词并不是固定的,看上去,唯一和这些关键词种类有关系的就是它们的层级结构了。
接下来,需要介绍一下 xpath 这个东西了。
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。
XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力。起初XPath的提出的初衷是将其作为一个通用的、介于XPointer与XSL间的语法模型。但是XPath很快的被开发者采用来当作小型查询语言。在这里,可以看到每个关键词是属于某个关键词种类的下一组结点的,所以可以用 following-sibling 的属性来获取到这组关键词元素。
上文已经通过 article_link 存储了所有文章的 url,这里还需要通过正则表达式判断文章的 article_id:
1
2
3
4
5# get into articles page
for article_link in article_links:
driver.get(article_link + "keywords")
article_id = re.findall("[0-9]+", article_link)[0]
time.sleep(3)创建四个字典,用来存储四个关键词种类:
1
2
3
4
5
6# get into keywords page
dic = {}
dic['IEEE Keywords'] = []
dic['INSPEC: Controlled Indexing'] = []
dic['INSPEC: Non-Controlled Indexing'] = []
dic['Author Keywords'] = []首先找到关键词种类的元素,然后用 following-sibling 找到其下的具体关键词:
1
2
3
4
5
6
7
8
9
10keywords_type_list = driver.find_elements_by_css_selector("li.doc-keywords-list-item.ng-scope strong.ng-binding") # ['IEEE Keywords', 'INSPEC: Controlled Indexing', 'INSPEC: Non-Controlled Indexing', 'Author Keywords']
for i in range(len(keywords_type_list)):
# 定位每个关键字种类,然后提取该关键字种类下的所有关键字
li = []
keywords_ele_list = driver.find_elements_by_xpath(
".//*[@id=" + article_id + "]/div/ul/li[" + str(i+1) +"]/strong/following-sibling::*/li/a")
for j in keywords_ele_list:
li.append(j.text)
dic[keywords_type_list[i].text] = li
article_keywords.append(dic)最后输出成 csv 文件即可:
1
2
3
4
5
6
7
8
9
10
11# already get all data, now output to the csv file
pprint(article_keywords)
with open("ieee_zhangbo_.csv", "w", newline="")as f:
csvwriter = csv.writer(f, dialect=("excel"))
csvwriter.writerow(['article_name', 'article_source', 'article_link',
'IEEE Keywords', 'INSPEC: Controlled Indexing',
'INSPEC: Non-Controlled Indexing', 'Author Keywords'])
for i in range(len(article_names)):
csvwriter.writerow([article_names[i], article_sources[i], article_links[i],
article_keywords[i]['IEEE Keywords'], article_keywords[i]['INSPEC: Controlled Indexing'],
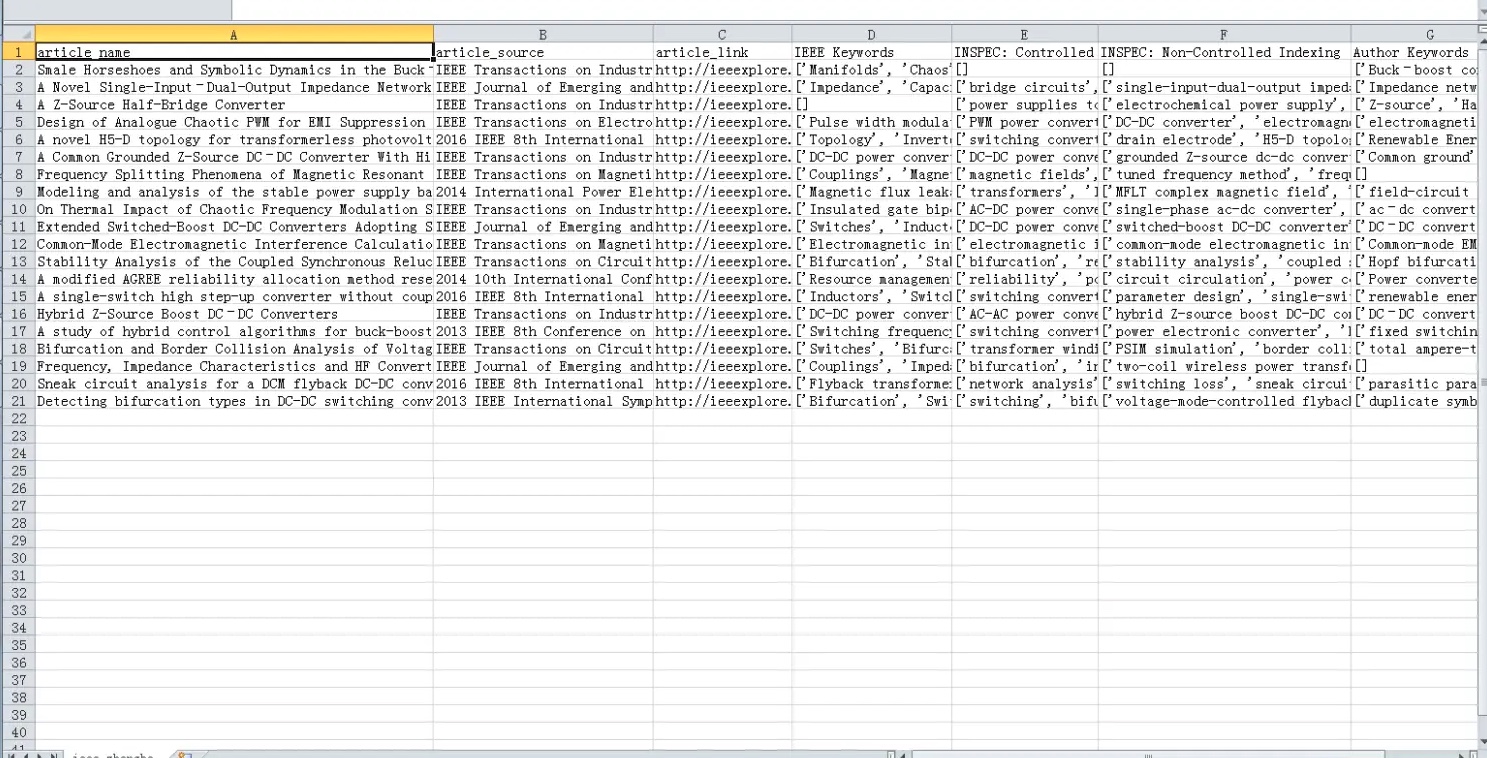
article_keywords[i]['INSPEC: Non-Controlled Indexing'], article_keywords[i]['Author Keywords']]输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67"C:\Program Files\Python36\python.exe" D:/PythonProject/immoc/IEEEXplorer_get_article.py
start to check if this is the last page !!!
This page is good to go !!!
article_name = Smale Horseshoes and Symbolic Dynamics in the Buck–Boost DC–DC Converter
article_link = http://ieeexplore.ieee.org/document/7926377/
article_name = A Novel Single-Input–Dual-Output Impedance Network Converter
article_link = http://ieeexplore.ieee.org/document/7827092/
article_name = A Z-Source Half-Bridge Converter
article_link = http://ieeexplore.ieee.org/document/6494636/
article_name = Design of Analogue Chaotic PWM for EMI Suppression
article_link = http://ieeexplore.ieee.org/document/5590287/
article_name = A novel H5-D topology for transformerless photovoltaic grid-connected inverter application
article_link = http://ieeexplore.ieee.org/document/7512376/
article_name = A Common Grounded Z-Source DC–DC Converter With High Voltage Gain
article_link = http://ieeexplore.ieee.org/document/7378484/
article_name = Frequency Splitting Phenomena of Magnetic Resonant Coupling Wireless Power Transfer
article_link = http://ieeexplore.ieee.org/document/6971783/
article_name = Modeling and analysis of the stable power supply based on the magnetic flux leakage transformer
article_link = http://ieeexplore.ieee.org/document/7037927/
article_name = On Thermal Impact of Chaotic Frequency Modulation SPWM Techniques
article_link = http://ieeexplore.ieee.org/document/7736981/
article_name = Extended Switched-Boost DC-DC Converters Adopting Switched-Capacitor/Switched-Inductor Cells for High Step-up Conversion
article_link = http://ieeexplore.ieee.org/document/7790823/
article_source = IEEE Transactions on Industrial Electronics
article_source = IEEE Journal of Emerging and Selected Topics in Power Electronics
article_source = IEEE Transactions on Industrial Electronics
article_source = IEEE Transactions on Electromagnetic Compatibility
article_source = 2016 IEEE 8th International Power Electronics and Motion Control Conference (IPEMC-ECCE Asia)
article_source = IEEE Transactions on Industrial Electronics
article_source = IEEE Transactions on Magnetics
article_source = 2014 International Power Electronics and Application Conference and Exposition
article_source = IEEE Transactions on Industrial Electronics
article_source = IEEE Journal of Emerging and Selected Topics in Power Electronics
start to check if this is the last page !!!
This page is good to go !!!
article_name = Common-Mode Electromagnetic Interference Calculation Method for a PV Inverter With Chaotic SPWM
article_link = http://ieeexplore.ieee.org/document/7120165/
article_name = Stability Analysis of the Coupled Synchronous Reluctance Motor Drives
article_link = http://ieeexplore.ieee.org/document/7460928/
article_name = A modified AGREE reliability allocation method research in power converter
article_link = http://ieeexplore.ieee.org/document/7107251/
article_name = A single-switch high step-up converter without coupled inductor
article_link = http://ieeexplore.ieee.org/document/7512635/
article_name = Hybrid Z-Source Boost DC–DC Converters
article_link = http://ieeexplore.ieee.org/document/7563395/
article_name = A study of hybrid control algorithms for buck-boost converter based on fixed switching frequency
article_link = http://ieeexplore.ieee.org/document/6566548/
article_name = Bifurcation and Border Collision Analysis of Voltage-Mode-Controlled Flyback Converter Based on Total Ampere-Turns
article_link = http://ieeexplore.ieee.org/document/5729352/
article_name = Frequency, Impedance Characteristics and HF Converters of Two-Coil and Four-Coil Wireless Power Transfer
article_link = http://ieeexplore.ieee.org/document/6783963/
article_name = Sneak circuit analysis for a DCM flyback DC-DC converter considering parasitic parameters
article_link = http://ieeexplore.ieee.org/document/7512450/
article_name = Detecting bifurcation types in DC-DC switching converters by duplicate symbolic sequence
article_link = http://ieeexplore.ieee.org/document/6572495/
article_source = IEEE Transactions on Magnetics
article_source = IEEE Transactions on Circuits and Systems II: Express Briefs
article_source = 2014 10th International Conference on Reliability, Maintainability and Safety (ICRMS)
article_source = 2016 IEEE 8th International Power Electronics and Motion Control Conference (IPEMC-ECCE Asia)
article_source = IEEE Transactions on Industrial Electronics
article_source = 2013 IEEE 8th Conference on Industrial Electronics and Applications (ICIEA)
article_source = IEEE Transactions on Circuits and Systems I: Regular Papers
article_source = IEEE Journal of Emerging and Selected Topics in Power Electronics
article_source = 2016 IEEE 8th International Power Electronics and Motion Control Conference (IPEMC-ECCE Asia)
article_source = 2013 IEEE International Symposium on Circuits and Systems (ISCAS2013)
start to check if this is the last page !!!
The last page !!!csv 文件:
原文发表于 https://www.jianshu.com/p/c8ed978dd0ab, by 2017.11.18 12:25:52