微服务架构下的Java Parallel Stream实践——优化RT与串联traceid
背景
- 在业务开发中,需要将一些图片mediaId批量调用多媒体服务的接口(FileService#copyMedia),从而实现图片替换的功能
- 具体链路如下,客户端RT可认为从一个请求从发出到响应的经过时间:
1 | 用户客户端 --> MyService --> FileService#copyMedia |
第一版代码
- 因为项目工期较紧,第一版代码重点主要在功能完整性和准确性上,当时的做法是批量解析图片id,再批量调接口,再批量替换原位
- 在跨团队的开发联调与端到端测试后,第一版代码发布上线了,功能符合预期,也没啥bug,就是我们的报警群经常报rpc timeout的报警,客户端接口的RT也涨了不少(特别是99分位RT)
- 经过定位发现,copyMediaId接口会去访问oss生成新的mediaId,当资源跨地域时,RT显著增大,而且有些特定行业的用户(如电商)可能请求中有30、40张图片,这对copyMediaId接口造成极大的压力,RT增大是在所难免的,从而直接影响了客户端接口的RT,虽无用户直接反馈,但我们推测这个RT还是会或多或少地影响用户体验,所以要考虑如何优化RT
阿里云对象存储OSS介绍:https://help.aliyun.com/document_detail/31827.html
第二版代码
- 我们的目标是优化客户端接口RT,而这次需求唯一引入的外部依赖就是copyMediaId接口,所以首先考虑的是copyMediaId接口的优化,但毕竟跨团队,优化意愿不强烈,于是就想着在我们内部闭环掉
- 调研后发现,发现Java8的Parallel Stream可以很好地帮我们解决问题,Parallel Stream利用了Java自身的ForkJoin线程池,借助函数式编程思想做了非常强大的封装,使得开发者编写多线程并发代码就像编写单线程代码那样简单(至少给我的感觉是这样)
ForkJoin:默认线程池是是CPU数量-1
The parallel streams use the default ForkJoinPool.commonPool which by default has one less threads as you have processors, as returned by Runtime.getRuntime().availableProcessors() (This means that parallel streams leave one processor for the calling thread).
https://stackoverflow.com/questions/45460577/default-forkjoinpool-executor-taking-long-time - 注意并发流不保证执行顺序,所以如果要保序的话得自己再弄一下(因为我得按顺序替换到原消息体的mediaId的位置,所以得保序),很快,就写出了第二版代码(省去无关代码):
1 | public MediaCopyResponse mediaCopy(..., List<String> validMediaIds) throws ServiceException { |
- 调了会参,决定了每批分批的数量,arthas帮了很大的忙
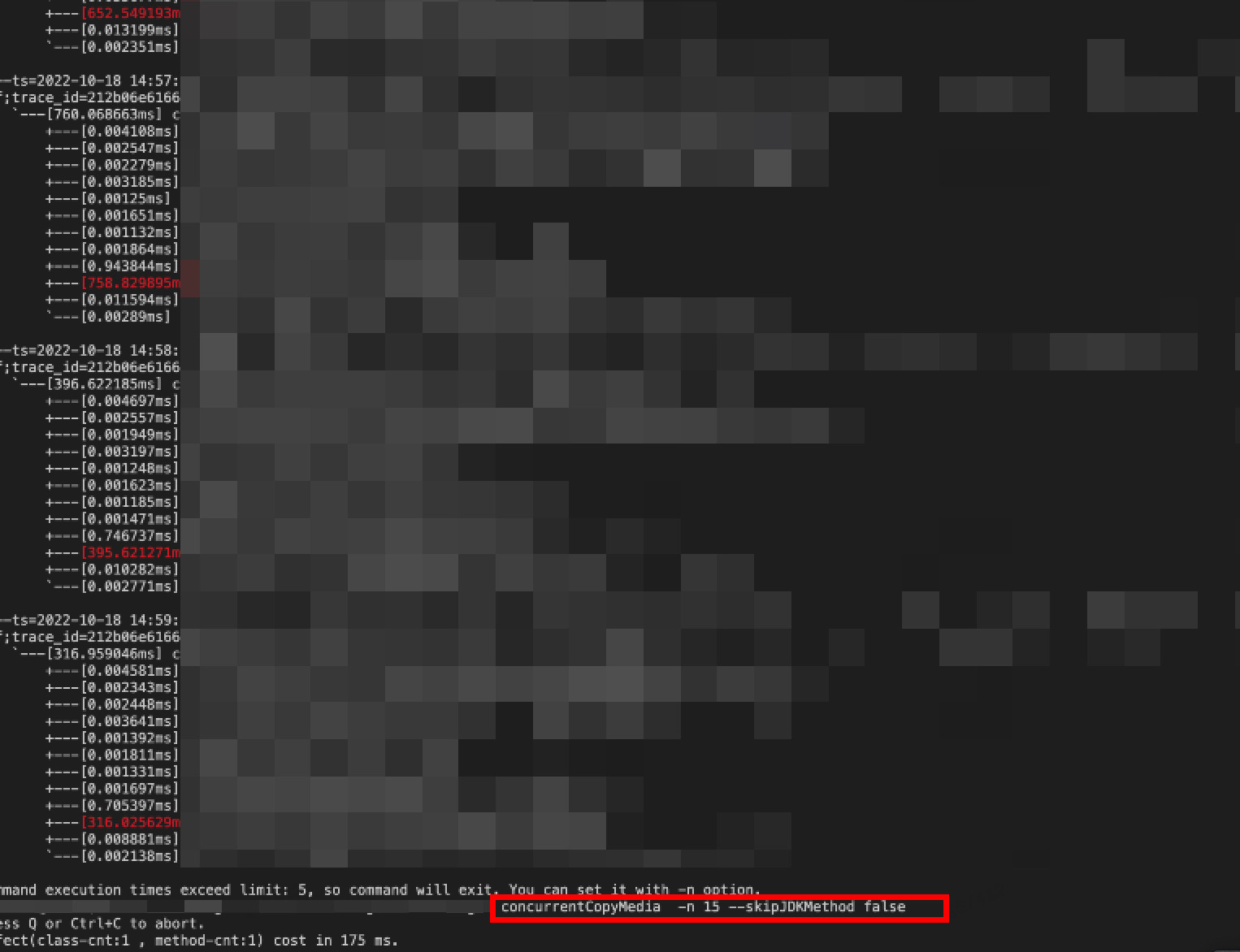
- 嗯,代码看上去很完美了,也没有bug,经过测试也不会有mediaId乱序的问题,上线!
- 上线一切岁月静好,但在后来的一次排查问题时,发现traceid断了,这会对我们的后期运维会带来极大的麻烦
阿里巴巴Eagleeye,一款分布式追踪工具,与Google的Dapper很像,能够把微服务架构中的各个服务串联起来,参考:https://www.alibabacloud.com/blog/alibaba-eagleeye-ensuring-business-continuity-through-link-monitoring_594157
美团技术团队的这篇文章很完整地描述了traceid丢失的现象与本质:https://mp.weixin.qq.com/s/T7P2-tiroXWI9xd8FhsuFA
第三版代码
- traceid信息其实放在ThreadLocal里面,写Java的同学或多或少都了解过,经过搜索,发现Eagleeye已有对策
- 『异步线程时需要手动传递上下文,当业务逻辑转移到异步线程时,需要先备份 EagleEye 的调用上下文到异步任务中,保证链路的正确性。』
- 加几行代码,收工!
1 | private MediaCopyResponse concurrentCopyMedia(..., Map<String, String> ext, List<String> validMediaIds) { |
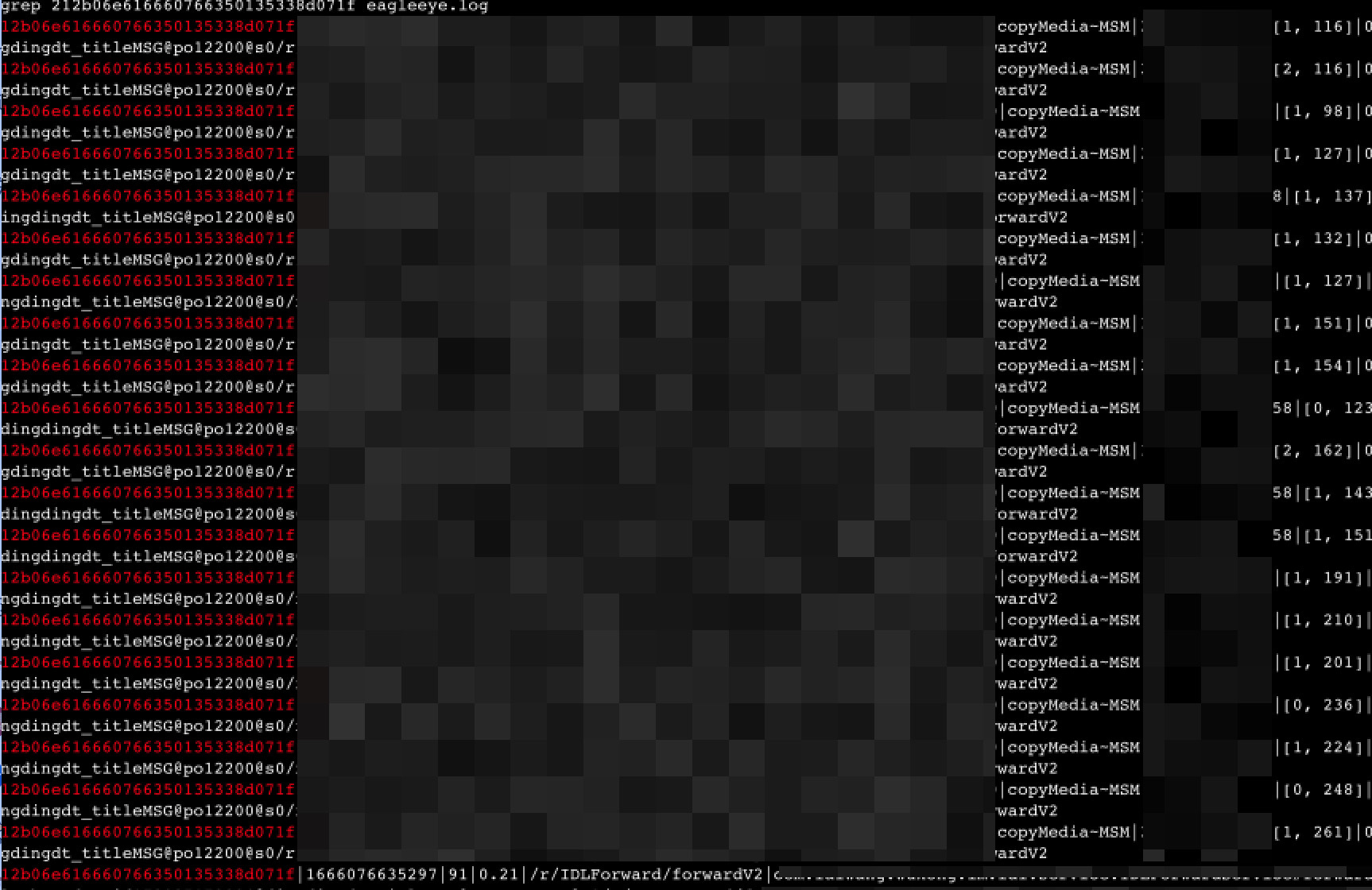
结果
串联traceid:
原文发表于 2023-02-19
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 一知半解!