Rocketmq原理
术语
- Topic 主题:即为发布或者订阅的主题,topic一般由多个队列组成,队列会平均的散列到多个Broker上面。Producer的发送机制会保证消息尽量平均的散列到所有队列上面去,最终的效果是所有的消息会平均的落在每个Broker上面。
- Broker : 主要负责消息的存储、投递和查询以及服务高可用保证。即消息队列服务器,生产者生产消息到 Broker ,消费者从 Broker 拉取消息并消费。一个 Topic 分布在多个 Broker上,一个 Broker 可以配置多个 Topic ,它们是多对多的关系。如果某个 Topic 消息量很大,应该给它多配置几个队列,并且尽量多分布在不同 Broker 上,以减轻某个 Broker 的压力 。Topic 消息量都比较均匀的情况下,如果某个 Broker 上的队列越多,则该 Broker 压力越大。
- NameServer : 本质上是一个注册中心,主要提供两个功能:Broker管理和路由信息管理 。Broker会将自己的信息注册到 NameServer 中,此时 NameServer 就存放了很多 Broker 的信息(Broker的路由表),消费者和生产者就从 NameServer 中获取路由表然后照着路由表的信息和对应的 Broker 进行通信(生产者和消费者定期会向 NameServer 去查询相关的 Broker 的信息)。
- Producer : 消息发布的角色,支持分布式集群方式部署,即生产者。Producer 与 NameServer 集群中的其中一个节点(随机选择)建立长连接,定期从 Name Server 取 Topic 路由信息,并向提供 Topic 服务的 Master 建立长连接,且定时向 Master 发送心跳。Producer 完全无状态,可集群部署。
- Consumer : 消息消费的角色,支持分布式集群方式部署。支持Push、Pull两种模式对消息进行消费。同时也支持集群方式和广播方式的消费,它提供实时消息订阅机制,即消费者。Consumer 与 Name Server 集群中的其中一个节点(随机选择)建立长连接,定期从 Name Server 取 Topic 路由信息,并向提供 Topic 服务的 Broker 建立长连接,且定时发送心跳。
- Producer Group(生产者组): 代表某一类的生产者,比如我们有多个秒杀系统作为生产者,这多个合在一起就是一个 Producer Group 生产者组,它们一般生产相同的消息。
- Consumer Group(消费者组): 代表某一类的消费者,比如我们有多个短信系统作为消费者,这多个合在一起就是一个 Consumer Group 消费者组,它们一般消费相同的消息。
整体流程
- 启动 Namesrv,Namesrv起 来后监听端口,等待 Broker、Producer、Consumer 连上来,相当于一个路由控制中心。
- Broker启动,跟所有的 Namesrv 保持长连接,定时发送心跳包。心跳包中,包含当前 Broker 信息(IP+端口等)以及存储所有 Topic 信息。 注册成功后,Namesrv 集群中就有 Topic 跟 Broker 的映射关系。
- 收发消息前,先创建 Topic 。创建 Topic 时,需要指定该 Topic 要存储在哪些 Broker上。也可以在发送消息时自动创建Topic。
- Producer 发送消息。启动时,先跟 Namesrv 集群中的其中一台建立长连接,并从Namesrv 中获取当前发送的 Topic 存在哪些 Broker 上,然后跟对应的 Broker 建立长连接,直接向 Broker 发消息。
- Consumer 消费消息。Consumer 跟 Producer 类似。跟其中一台 Namesrv 建立长连接,获取当前订阅 Topic 存在哪些 Broker 上,然后直接跟 Broker 建立连接通道,开始消费消息。
特性
定时消息
定时消息(延迟队列)是指消息发送到broker后,不会立即被消费,等待特定时间投递给真正的topic
定时消息会暂存在名为SCHEDULE_TOPIC_XXXX的topic中,并根据delayTimeLevel存入特定的queue,同一个queue只存相同延迟的消息,保证具有相同发送延迟的消息能够顺序消费。broker会调度地消费SCHEDULE_TOPIC_XXXX,将消息写入真实的topic。
需要注意的是,定时消息会在第一次写入和调度写入真实topic时都会计数,因此发送数量、tps都会变高。
应用:在几千人的群里发一条消息,假设有 1/4 的成员同时开着聊天窗口,如果不对服务端已读服务和客户端需要更新的已读数做合并处理,更新的 QPS 会高达到 1000/s。钉钉能够支持十几万人的超大群,超大群的活跃对服务端和客户端都会带来很大冲击,而实际上用户的需求只需实现秒级更新。
消费模型
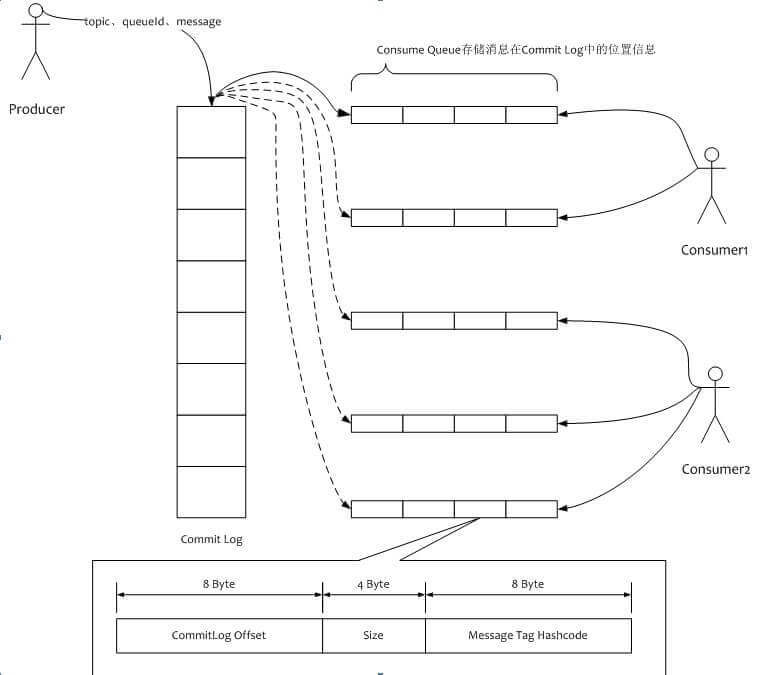
- CommitLog: 为一个个文件,所有的topic信息过来,都是存储在CommitLog中,每个小格子代表1G的文件,写满一个G之后,写下一个G(Append Only模式)
- ConsumerQueue: 消息逻辑队列, 当消息存储到CommitLog中,会异步的创建它的索引,然后将索引存储到ConsumerQueue中(异步构建Consumer Queue)。
- 索引内容(定长20字节):
- CommitLog Offset: 消息在CommitLog中位移
- Size: 消息大小
- Message Tag HashCode: 消息Tag的hashcode值,用于Broker侧的过滤消息(每条消息对应一个Message Tag)。
MetaQ的Consumer都是从Broker拉消息(Pull)来消费(包括后文的PushConsumer与PopConsumer),但是为了能做到实时收消息,MetaQ使用长轮询方式,可以保证消息实时性同 Push 方式一致。(通过API的封装让我们感觉是Push的)
Consumer在拉消息时,通过offset判断消息在CommitLog中的位置,然后取出大小为size的消息,最后通过tag进行消息过滤验证
RocketMq4.0以前的客户端模式
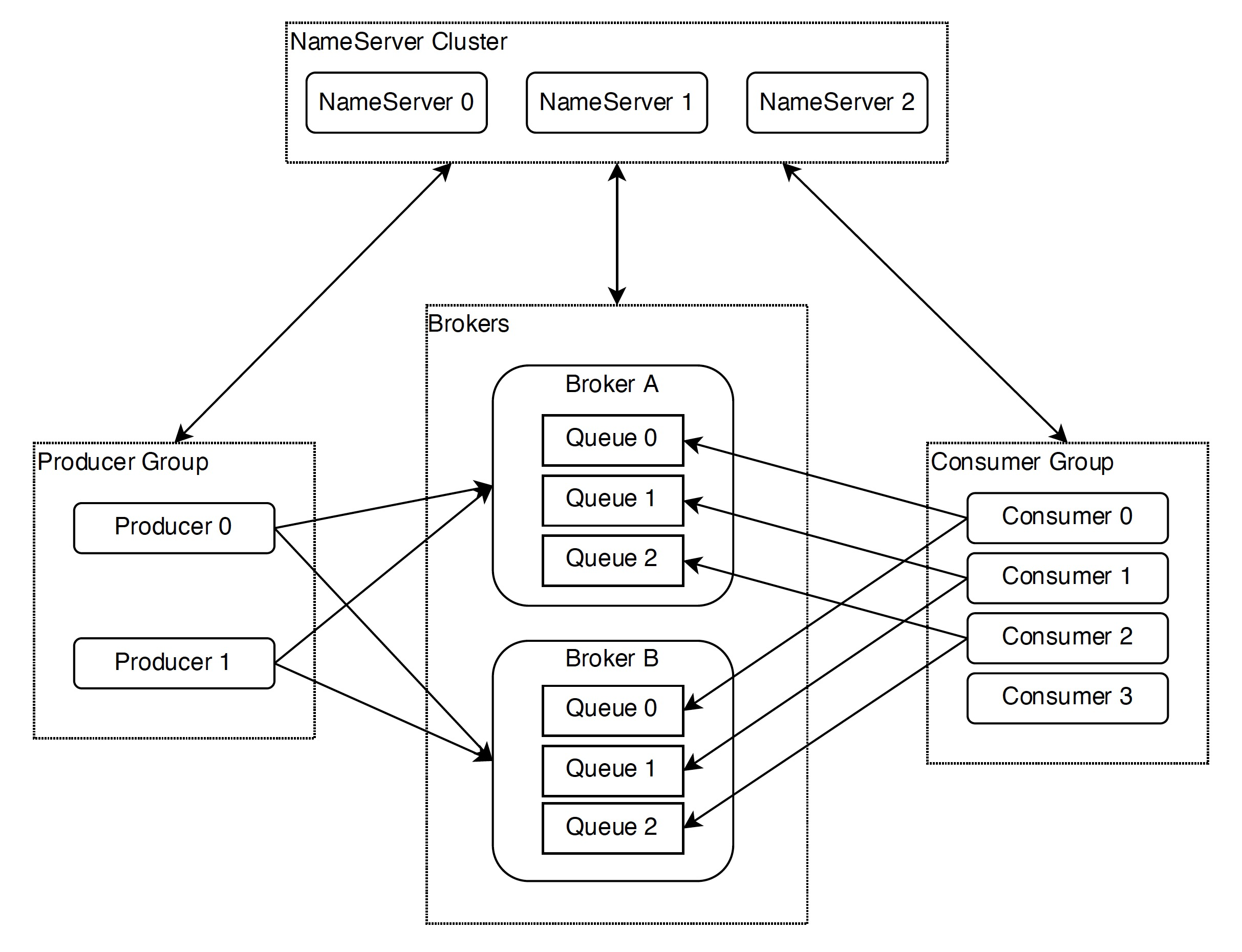
Producer 使用轮询的方式分别向每个 Queue 中发送消息,一般消费端都不止一个,客户端启动的时候会在 Topic,Consumer group 维度发生负载均衡,为每个客户端分配需要处理的 Queue。负载均衡过程中每个客户端都获取到全部的的 ConsumerID 和所有 Queue 并进行排序,每个客户端使用相同负责均衡算法,例如平均分配的算法,这样每个客户端都会计算出自己需要消费那些 Queue,每当 Consumer 增加或减少就会触发负载均衡,所以我们可以通过 RocketMQ 负载均衡机制实现动态扩容,提升客户端收发消息能力。
- 如果某个Consumer假死,会造成某个队列的消息堆积;
- reblance规定了一个消费者组下的所有消费者如何达成一致,来重新分配订阅主题的每个分区和消费者的关系。Rebalance过程对Consumer Group消费过程有极大的影响。
- 在rebalance过程中,所有Consumer实例都会停止消费造成消息大量积压,必须等待Rebalance完成才能继续消费,大量积压的消息处理容易造成短时间CPU使用率过高。并且原来消费者实例连接在分区所在Broker的TCP 连接被中断,需要重新创建连接其他 Broker的Socket 资源,有很大的性能开销;
- 同时,由于消费位点Offset是消费者异步提交,如果提交过程中发生Rebalance,容易造成提提交成功前发生重复消费,影响正常消息处理效率。
- 另外,负载均衡只能到Queue维度,导致需要不时地关注 Queue 数量。比如线上流量增长过快,需要进行扩容,而扩容后发现机器数大于 Queue 数量,导致无论怎么扩容都无法分担线上流量,最终只能联系 RocketMQ 运维人员调高 Queue 数量来解决。
RocketMq5.0全新的PopConsumer消费模式
- POP 消费和原来 Pull 消费对比,最大的一点就是弱化了队列这个概念,Pull 消费需要客户端通过 Rebalance 把 Broker 的队列分配好,从而去消费分配到自己专属的队列。新的 POP 消费中,客户端的机器会直接到每个 Broker 的队列进行请求消费, Broker 会把消息分配返回给等待的机器
- POP消费主要是将RocketMQ消费者组中的消费者变成无状态,消费者之间消费都是分区平等的,一个消费者可以根据负载均衡算法消费该主题下的所有分区,分区的消费位点交给Broker来维护,就不会有Rebalance了,降低了消费延迟的概率;
- RocketMQ 5.0 提供轻量级的客户端,使之具备良好的集成与被集成能力。同时,将负载均衡、逻辑位点管理这些复杂逻辑都放到服务端,实现无状态化。
与Kafka对比
存储
Kafka
Kafka和MetaQ一样,都是采用topic作为发布和订阅的主题,topic是个逻辑概念,而partition是物理上面的概念,每个partition对应一个log文件,该log文件中存储的就是producer生产的数据。producer生产的数据会被不断追加到log文件的末端,且每条数据都有自己的offset。
每个partition以目录的形式存储在broker上,该目录底下存储着的是该partition内容被平均分配成的多个大小相等的数据文件,我们称之为segment(段)。每个segment文件分为两个部分,index file和data file,此两个文件一一对应,后缀”.index”和”.log”分别表示segment的索引文件和数据文件
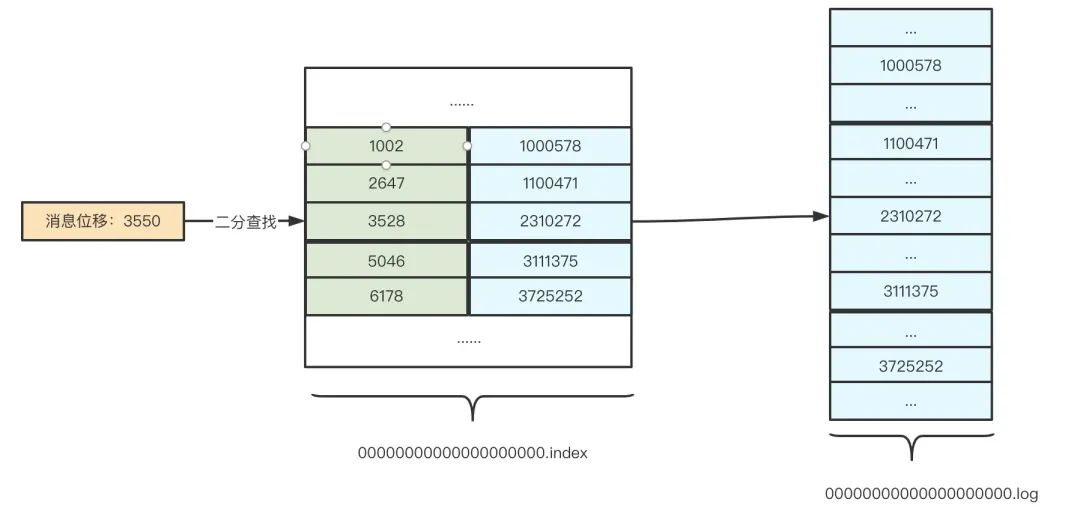
segment index file采取稀疏索引存储方式,它减少索引文件大小,通过mmap可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,先通过index文件中获取该message的一个位置范围,然后根据这个位置范围在log文件中找到该message的信息。稀疏索引的核心是不会为每个记录都保存索引,而是写入一定的记录之后才会增加一个索引值,因此 Kafka 可以利用二分查找算法来搜索目标索引项
Metaq
物理队列我们一般用commitlog来表示,在一个broker上面,所有发到broker上的信息都会按顺序写入物理队列中,物理队列又由许多文件组成,当一个文件被写满(默认大小为1G)时,则创建一个新的文件继续写入,文件以offset的方式来命名,与kafka中的partition命名类似。
逻辑队列:逻辑队列我们一般用consumequeue来表示,在消息被写入物理队列之后,如果消费端想从broker拉取消息,就需要一个索引文件,MetaQ中将每个Topic分为了几个区,每个区对应了一个消费队列
CommitLog以物理文件的方式存放,每台Broker上的CommitLog被本机器上所有的ConsumeQueue共享,MetaQ中采取了一些机制,尽量往CommitLog中顺序写,但是可以支持随机读。ConsumeQueue虽然是随机读,但是根据局部性原理,可以预先读出一块commitLog
Kafka的broker如果有多个partition,写入会有磁盘瓶颈,但Metaq的commitLog是多consumeQueue共享,是顺序写的,速度很快
MetaQ为什么不像kafka使用zk作为元数据节点,而要使用自己实现的NameServer?
我们知道,kafka使用zk作为元数据节点,起到了Broker注册、Topic注册、生产者和消费者负载均衡以及使用zk进行leader角色的选举,当leader所在的broker挂了,将会经过以下两步操作重新选举leader:第1步,先通过Zookeeper在所有机器中,选举出一个KafkaController;第2步,再由这个Controller,决定每个partition的Master是谁,Slave是谁。因为有了选举功能,所以kafka某个partition的master挂了,该partition对应的某个slave会升级为主对外提供服务。
MetaQ不具备选举,Master/Slave的角色也是固定的。当一个Master挂了之后,你可以写到其他Master上,但不能让一个Slave切换成Master。那么MetaQ是如何实现高可用的呢,其实很简单,MetaQ的所有broker节点的角色都是一样,上面分配的topic和对应的queue的数量也是一样的,MetaQ只能保证当一个broker挂了,把原本写到这个broker的请求迁移到其他broker上面,而并不是这个broker对应的slave升级为主。
MetaQ,是不需要进行选举的,为了方便集群维护,直接使用NameServer这一个轻量级工具来存储元数据信息即可。
消息可靠性
同步异步复制
同步复制和异步复制的区别在于producer发送消息到master节点之后,是否会等待slave节点复制结束之后再进行返回。
a. 同步复制
当生产者将消息发送到broker的master节点时,master会首先将消息复制到所有的slave节点,等待复制动作完成之后,才会给客户端返回“发送成功”的响应,消息可靠性得到保证。
b. 异步复制
当生产者将消息发送到broker的master节点时,并不会等待复制动作的结束,会直接返回一个发送成功的状态响应。当出现网络抖动,会导致消息复制不成功,这个时候消息可靠性不够高,消费者消费消息不及时的情况。
同步异步刷盘
同步异步刷盘的区别在于,消息存储在内存(memory)中以后,是否会等待执行完刷盘动作再返回,即是否会等待将消息中的消息写入磁盘中。
a. 异步刷盘
当消息写入到broker的内存中之后即返回写成功状态,并不会等待消息从内存中写入磁盘就返回。所以写操作的返回快,吞吐量大;当内存里的消息量积累到一定程度时,统一触发写磁盘操作,快速写入。
b. 同步刷盘
当消息被写入到内存之后,会立刻会立刻通知刷盘线程刷盘,然后等待刷盘完成,刷盘线程执行完成后唤醒等待的线程,返回消息写成功的状态。所以当返回写成功状态的时候,消息已经被写入磁盘了。
MetaQ和kafka都支持同步异步复制以及同步异步刷盘。
MetaQ和kafka的消息读写方式
零拷贝
内存读写磁盘有一个中间层:pageCache
在磁盘写入的时候会写入到pageCache中去的,然后pageCache中可以将一些小的写入合并成一个大的写入。当然我们也可以使用fsync进行强制刷盘,强制刷盘会影响写入性能
读取消息的时候如果在pageCache中有命中则直接返回,如果在pageCache中无法命中则会产生缺页中断,需要从磁盘中加载数据到缓存中,然后返回数据。并且根据局部性原理,在读数据的时候也会进行预读,把该也相邻的磁盘快读入到页缓存中去。
mmap
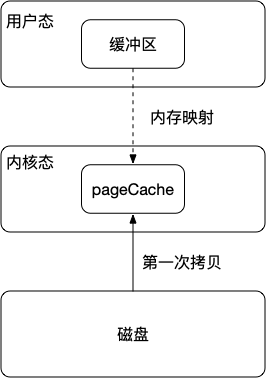
- 由于我们读取数据的时候,需要将数据从磁盘拷贝到pageCache中,但是由于pageCache属于内核空间,用户空间无法访问,所以还需要将数据从内核空间拷贝到用户空间。
- 所以数据需要两次拷贝应用程序才能够访问的到,我们可以通过mmap来减少数据从内核态到用户态的拷贝。通过将程序虚拟页面映射到页缓存中,这样就不需要将数据从内核态拷贝到用户态,也可以避免产生重复数据。也不必要再通过调用read和write方法对文件进行读写,而是通过映射地址和偏移量来直接操作pageCache。
sendfile
- sendfile仅用一次系统调用就完成了发送数据的需求,相比于read+write或者说mmap+write来说上下文切换次数变少了,但是数据还是有冗余的。在linux2.4中采用 sendfile+带[分散-收集]的DMA。真正实现了无冗余的功能。
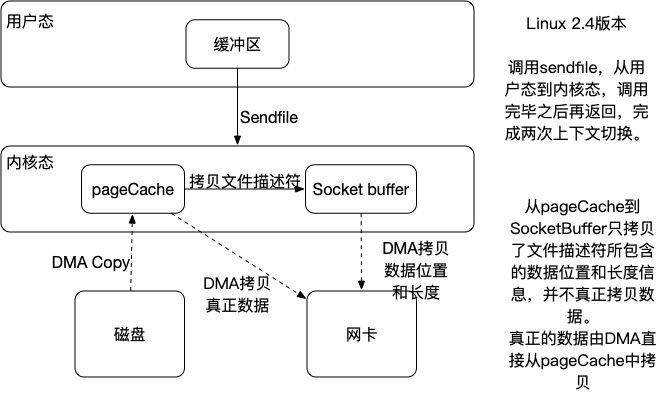
metaq与kafka的消息读写方式
目前kafka只支持sendfile的消息读写方式,MetaQ支持mmap的消息读写方式,另外MetaQ还支持sendfile的消息写方式。
由于kafka主要是用于日志传输,处理海量数据,对于数据的正确度要求不是很高,并且在发送消息的时候一般会进行消息的汇聚,然后批量发送消息,所以整体上来说kafka的读写数据量会比较大,这个时候使用sendfile能够获取更高的性能,而MetaQ主要是用来针对阿里的复杂应用场景,对于数据的可靠性、数据的实时性要求会比较高,由于对数据的实时性要求较高,一般不会进行汇聚批量发送消息,所以读写数据量不会很大,这个时候使用mmap可以获得更好的性能,当如果发现写入的数据量比较大时,也可以切换为sendfile进行写入。